之前给大家写过一篇数据清洗的文章,解决的问题是你拿到原始数据后如何快速地对数据进行处理,处理到你基本上可以拿来分析的地步,其中介绍了如何选变量如何筛选个案,变量重新编码,如何去重,如何替换缺失值,如何计算变量等等——R数据分析:数据清洗的思路和核心函数介绍
今天呢,就更进一步,对于一个处理好的数据,我们就可以进行统计分析了,本文的思路就是对照期刊论文的一般流程写写如何快速的实现一篇论文的统计过程并简洁高效地展示结果。依然提醒大家,请先收藏本文再往下读哈。
先做描述统计
基本上文章结果部分一上来首先展示的就是描述统计,就是你有多少样本,样本特征是啥样的—-连续变量的均值标准差是多少,分类变量的频数百分比是多少等等,这些都是描述统计
做法1:
比如我现在拿到手的处理好的数据是这样:

图1
比如我想看看男女之间它们每个变量的均值是多少,我就可以写出如下代码:
data %>%
group_by(gend.f) %>%
summarize(mean_figures=mean(figures),
mean_cards=mean(cards),
mean_words=mean(wordlist))运行之后可以看到输出中就按照性别输出了三个变量的均值。
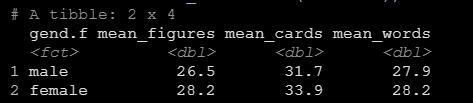
如果我们想要描述的变量很多,可以用summarize_at函数进一步简化代码如下:
data %>%
group_by(gend.f) %>%
summarize_at(vars("figures","cards","wordlist"), mean)运行后得到结果如下:
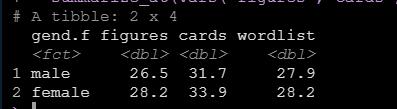
上面是均值的例子,其余的比如标准差只需要将mean函数一换就可以。
方法2:
方法1感觉还是有点呆哈,给大家介绍方法2:我们还可以直接用psych包中的describe函数也可以得到连续变量常用的描述统计量,比如运行下面的代码:
describe(data, fast = T)就可以得到数据的描述统计,包括个数,均值,标准差,极值极差标准误,比方法1要方便一丢丢的:
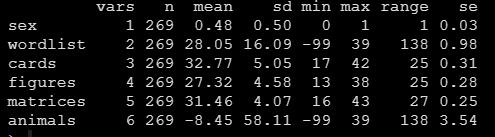
如果将fast参数去掉,则偏度峰度,中位数等等也会出现:

以上两种方法都是针对连续变量的部分处理方法,适用性没有那么好,再接着看下面的做法
做法3:使用tableone包
做描述统计第三个方法就是用tableone包,依然是对于图1中的数据,我现在想做一个描述统计,连续变量用均值±标准差,分类变量用频数百分比表示,我就可以写出如下代码:
(tab_nhanes <- CreateTableOne(data = data))运行后得到如下描述统计结果:
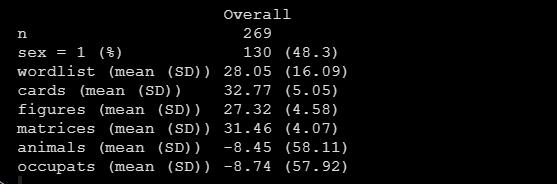
可以看到,sex变量是用频数百分比进行描述的,其余的连续变量都是以均值标准差呈现的。
在使用tableone包的时候如果你通过正态性检验发现某个变量不是正态分布的,这个时候需要用中位数和四分位数间距进行描述,此时在打印tableone对象的时候加上nonnormal = "变量名"参数就好了,比如我现在知道我的数据中年龄是不服从正态分布的,我就可以写出如下代码:
print(tab_nhanes,
showAllLevels = TRUE,
nonnormal = "Age"
)大家肯定见过这样的表格展示的描述统计,就是分组描述统计:
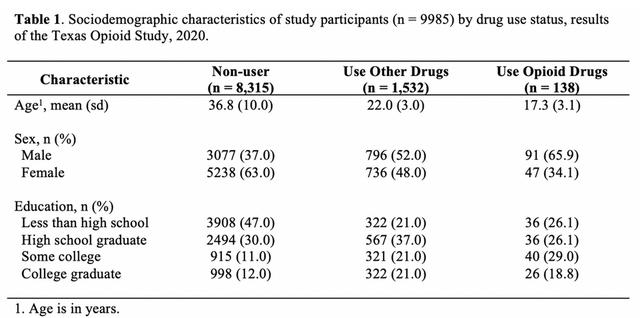
比如干预实验中对照组和干预组的特征比较,两组随访数据的基线特征比较等等。
这样的表格用tableone也是非常容易实现的,比如我的原始数据长这样:
图2
我现在想以Gender这个变量进行分组描述统计,我便可以写出如下代码:
strata <- CreateTableOne(data = data,
vars = c("Age", "Race", "Education"),
factorVars = c("Race","Education"),
strata = "Gender"
)
print(strata,
nonnormal = "Age",
cramVars = "Gender")上面的代码中,strata参数设置分组变量,factorVars指定变量类型为因子,vars参数指定我们要进行统计描述的变量,运行后出来的结果如下:
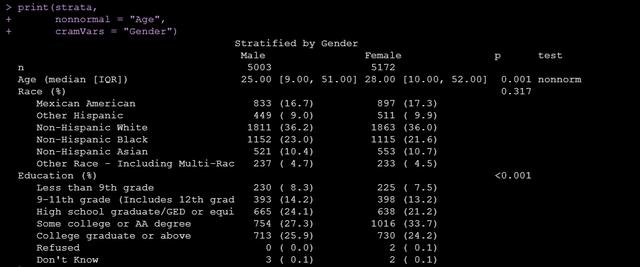
可以看到既有所有变量的统计描述还有组间比较的p值,另外我们可以很方便地通过以下代码将做出来的tableone输出成csv:
tab_csv <- print(strata,
nonnormal = "Age",
printToggle = FALSE)
write.csv(tab_csv, file = "Summary.csv")运行后即可在目录中找到相应的csv文件,然后直接复制粘贴到论文中。

图3
方法4:gtsummary
最后要给大家介绍的方法就是使用gtsummary中的tbl_summary函数,比如依然是上面的数据(图1中的数据),我使用gtsummary函数写出代码如下:
data %>% tbl_summary(
by=Gender,statistic = all_continuous() ~ "{mean} ({sd})",
) %>% add_p() %>% modify_caption("**Table 1. Please follow Wechat Channel--Codewar**")
可以看到,代码基本就1行,add_p是添加分组比较的p值(按需使用),modify_caption是更改表的标题,运行上面的代码,即可得到又一张出版级的表格如下(内容和图3也是一样的):
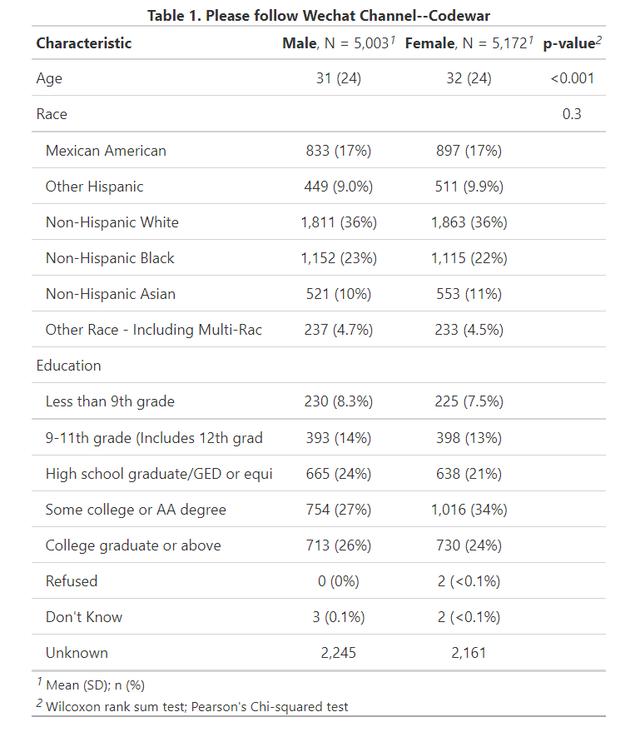
图3
真棒!这个表格也可以通过write.csv输出为excel然后直接贴到你的论文中。
再做相关分析
描述统计做完了之后我们有可能会需要做一下各个变量间的两两相关,期刊中常见的比较标准的相关结果表示方法如下,变量均值和标准差占两列,然后相关矩阵放后面:
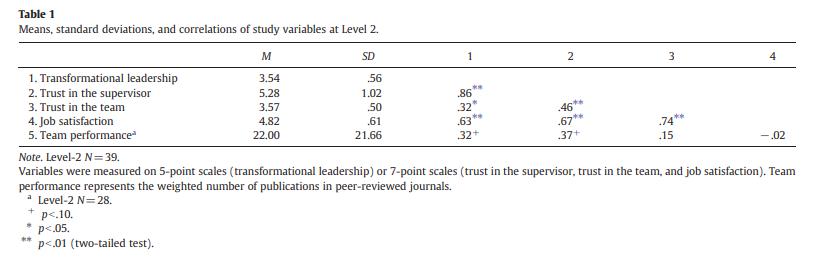
这样的表格也有十分简单的做法,大家可以直接使用mlmCorrs这个包,比如对于图1中的数据,我想拉一个和上图一样布局的结果表格,我只需要直接运行下面的代码:
data %>%
select(wordlist:occupats) %>%
mlmCorrs::corstars()便可以得到结果如下,真的是很方便呀:
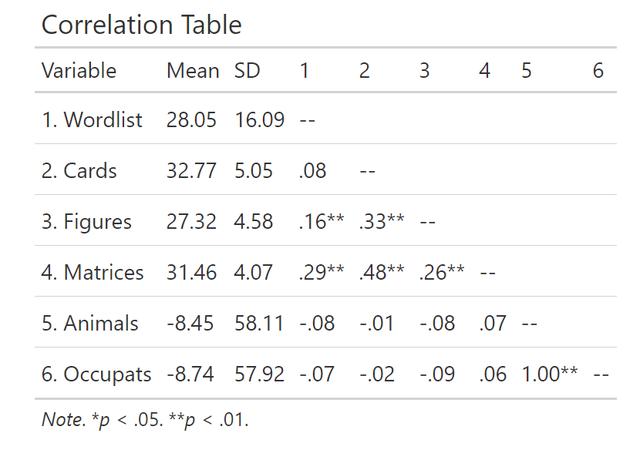
其实在R语言中拉相关的方法很多,但是就是这个好用,最好用。其它的还有ggpairs,还有corrr::correlate()还有Hmisc::rcorr都可以,有兴趣的同学可以自己取探索一番!
再做主分析
变量间的相关关系做完之后,大家要做多因素分析了,比如你要做个多元线性回归,比如你要做个逻辑斯蒂回归,或者做个生存分析,这些分析是你论文中最重要的部分,也是你的主要研究结论的体现。
这儿也给大家展示几个例子,首先写个简单的多元线性回归,其余的直接改相应的主分析函数就行。
方法1:tab_model
依然是图1中的数据,我现在随意跑了两个线性回归模型,代码如下:
model1 <- lm(cards ~ wordlist, data=data_txt)
model2 <- lm(cards ~ figures, data=data_txt)我想要展示模型的信息,只需要运行下面的代码就可以:
sjPlot::tab_model(model1, model2)得到的结果:
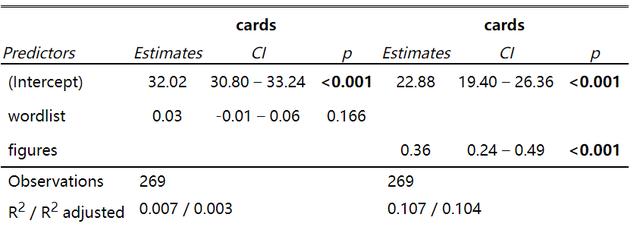
可以看到两个线性回归模型的结果被并列地展示出来了,结果还是挺好的,这里用到的tab_model当然不止可以可以用到普通的线性回归中,像广义线性模型和混合模型都是可以的。
方法2:gtsummary
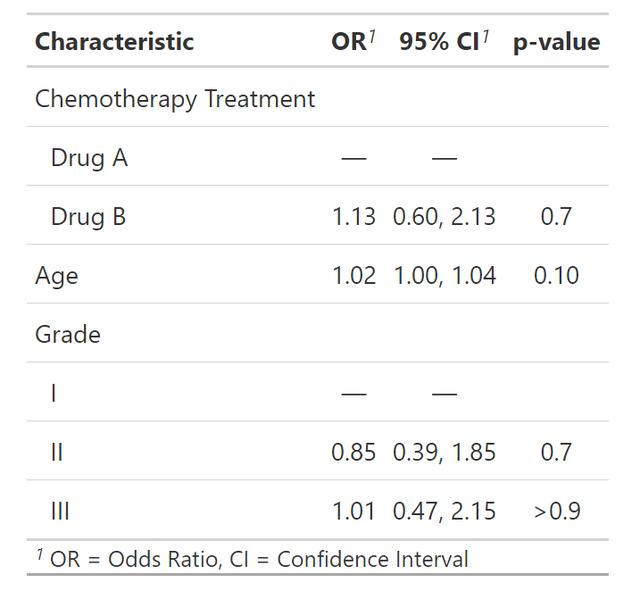
刚刚写了线性回归的例子,再给大家看看logistics回归和cox回归的模型展示,我先用同一批数据拟合一个logistics模型和一个cox模型:
glm(response ~ trt + age + grade, trial, family = binomial) %>%
tbl_regression(exponentiate = TRUE)
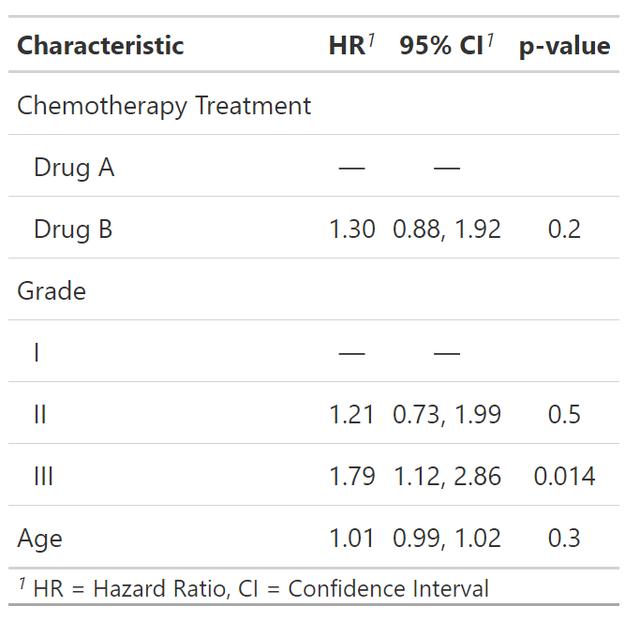
coxph(Surv(ttdeath, death) ~ trt + grade + age, trial) %>%
tbl_regression(exponentiate = TRUE)logistics模型的结果输出如下:
cox模型的结果如下:
此时我可以用tbl_merge函数将两个模型合并起来展示(这也是多个模型时的常规展示方法),代码如下:
tbl_merge_ex1 <-
tbl_merge(
tbls = list(t1, t2),
tab_spanner = c("**Tumor Response**", "**Time to Death**")
) %>% modify_caption("**关注公众号哟-Please follow Wechat Channel--Codewar**")运行后输出结果如下:
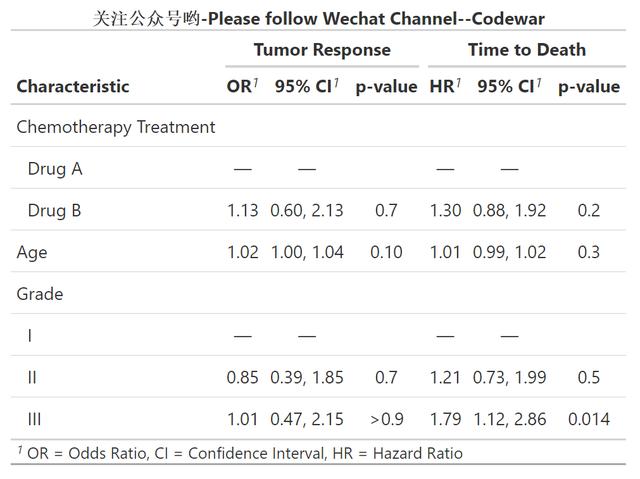
可以看到,同样的变量,跑了两个不同的模型,依然可以通过tbl_merge恰当地合并展示出来,很清晰,当然论文中肯定不会这么用,一般都是模型变量依次添加从而形成几个模型并排展示,这样的情况用tbl_merge也是可以的,可以动手试试哈。
小结
今天以假设的数据分析的流程为线,写了常规流程中的描述统计,相关,回归的做法,重点在如何快速地呈现出版级的结果,因为涉及的比较多,写的例子就比较浅显了,不过这里面提到的每一个包都值得大家细细探索。
感谢大家耐心看完,自己的文章都写的很细,重要代码都在原文中,希望大家都可以自己做一做,请转发本文到朋友圈后私信回复“数据链接”获取所有数据和本人收集的学习资料。如果对您有用请先记得收藏,再点赞分享。
也欢迎大家的意见和建议,大家想了解什么统计方法都可以在文章下留言,说不定我看见了就会给你写教程哦,有疑问欢迎私信,有合作意向请直接滴滴我。
如果你是一个大学本科生或研究生,如果你正在因为你的统计作业、数据分析、模型构建,科研统计设计等发愁,如果你在使用SPSS, R,Python,Mplus, Excel中遇到任何问题,都可以联系我。因为我可以给您提供最好的,最详细和耐心的数据分析服务。
如果你对Z检验,t检验,方差分析,多元方差分析,回归,卡方检验,相关,多水平模型,结构方程模型,中介调节,量表信效度等等统计技巧有任何问题,请私信我,获取详细和耐心的指导。
If you are a student and you are worried about you statistical #Assignments, #Data #Analysis, #Thesis, #Reports, #Composing, #Quizzes, Exams.. And if you are facing problem in #SPSS, #R-Programming, #Excel, Mplus, then contact me. Because I could provide you the best services for your Data Analysis.
Are you confused with statistical Techniques like z-test, t-test, ANOVA, MANOVA, Regression, Logistic Regression, Chi-Square, Correlation, Association, SEM, multilevel model, mediation and moderation etc. for your Data Analysis…??
Then Contact Me. I will solve your Problem…
加油吧,打工人!
往期精彩
R数据分析:什么是人群归因分数Population Attributable Fraction
R数据分析:手把手教你画列线图(Nomogram)及解读结果
R数据分析:二分类因变量的混合效应,多水平logistics模型介绍
Mplus数据分析:性别差异gendergap的相关研究如何做?
R数据分析:50人中至少两人相同生日的概率有多大?模拟给你看
R数据分析:嵌套数据分析为什么要用加随机效应?终于解释清楚了
R数据分析:Lasso回归筛选变量构建Cox模型并绘制列线图
R数据分析:纵向分类结局的分析-马尔可夫多态模型的理解与实操
R机器学习:分类算法之logistics回归分类器的原理和实现
如若转载,请注明出处:https://www.vsaren.com/39141.html
相关推荐
-
汽车销售技巧和话术经典语句,汽车销售技巧和话术经典语句100句?
引言:做销售的朋友对销售话术和应变能力这两个词汇一定不陌生,可要是一二三马上让你说出个子丑寅卯来,估计又是如鲠在喉。如果作为幸运者被我猜中,请看完这篇文字,相信会有启发。 一、销售…
-
项目管理资格证书报考条件(报考项目经理证需要什么条件)
虽然说现在PMP越来越了 但其实它相较于其他大家总能听到的那些证书还是比较低调的 可以说是低调奢华有内涵了。 既然很多宝子不知道,那咱今天就简单科普一下关于PMP的基本常识吧~ ?…
-
抖音怎么分期付款怎么关闭了,怎么取消抖音分期?
各大电商双12的预备战役已经打响,但从目前的声量来看,这个承接双11和双旦的促销节日,似乎并没有激起很大的水花。 01 双12在即,各大电商促销活动来袭 即使不像双11那样热搜不断…
-
民宿创业计划书(大学生版)主要经营范围,民宿创业计划书(大学生版)概论?
除了选址、设计之后一个重要的元素就施工了。奶爸一直在拿房,对施工的控制也做到极致。 1、施工前 ①设计师对接准备 很多人问奶爸一个问题“设计师后期如何在装修施工过程中衔接施工,如何…
-
养殖业什么最赚钱,养殖业什么最赚钱农村?
对于许多农村人来说,养殖业已经成为了不可观的经济来源,尤其在当今社会,养殖业的市场需求越来越大。但如何在养殖业中赚到更多的钱呢?这里将为大家分享九种最赚钱的养殖生物。 一、水产养殖…
-
ks直播下载手机版,ks直播平台下载?
一年一度的KS游戏星光大赏又要开始了,作为全网高人气的游戏直播平台,KS直播旗下有很多知名主播和公会,他们为观众们提供了丰富的直播内容,KS游戏为了表彰平台优秀的主播和公会,特意举…
-
怎么网上赚钱一天20(怎么网上赚钱一天几块)
2019年,我在北京做包装盒,同事介绍说做自媒体可以赚钱,我当时半信半疑。就跟他一起注册了头条号,当时不懂,乱注册一通,什么领域,垂直一概不懂。 我注册的影视号,但是里面主要是三农…
-
0投资稳定赚钱,零投资的赚钱方法?
逆向思维:普通人赚钱必须0成本,就是空手套白狼。 永远不要用你的固有思维认知,去判断这个瞬间万变的世界。 古人讲:大千世界,皆为虚幻,见相非相,既见如来。 就是说很多你看到,听到,…
-
app拉新推广平台骗局,APP拉新推广平台?
哈喽大家好,我是笑傲,有很多的朋友及粉丝问我,什么是拉新呢,拉新还能不能做,首先拉新行业从很久之前就兴起了,举个例子,就比如去买电脑,买完电脑之后有很多业务员是不是要给你电脑上安装…
-
去哪个网站配音赚钱多呢(去哪个网站配音赚钱多些)
本内容来源于@什么值得买APP,观点仅代表作者本人 |作者:橘生330 嗨,大家好,我是橘生。 随着视频自媒体的日益发展,越来越多的小伙伴都投身到自媒体行业中。前面几篇文章中有说到…